OpenAI, yapay zekâ alanında büyük bir adım olarak nitelendirilen yeni modeli “o1″i kullanıma sundu. Bu model, daha karmaşık problemleri çözme yeteneğiyle dikkat çekiyor ve şirketin insan benzeri yapay zekâ geliştirme hedefine yönelik önemli bir adım olarak değerlendiriliyor. O1, çok aşamalı sorunları çözmede ve kod yazmada önceki modellere göre daha başarılı, ancak bu performansın bir bedeli var. o1, GPT-4o modeline kıyasla daha pahalı ve daha yavaş çalışıyor.
O1 modeli, aynı zamanda daha küçük ve ekonomik bir sürüm olan o1-mini ile birlikte tanıtıldı. Şu an için sadece ChatGPT Plus ve Team kullanıcılarına sunulan bu model, önümüzdeki hafta Enterprise ve Edu kullanıcıları için de erişime açılacak. Ücretsiz kullanıcıların o1-mini’ye ne zaman erişebileceği ise henüz belirlenmiş değil. Geliştiriciler için API kullanımı oldukça maliyetli; o1-preview API’si, 1 milyon giriş token’ı için 15 dolar, 1 milyon çıkış token’ı içinse 60 dolar ücretle sunuluyor. Karşılaştırmak gerekirse, GPT-4o aynı miktar giriş için 5 dolar, çıkış için ise 15 dolar maliyetle kullanılabiliyor.
Yeni eğitim yöntemleri ve “zincirleme düşünme”
OpenAI, o1 modelini önceki modellere kıyasla tamamen farklı bir eğitim sürecinden geçirdi. Şirket, o1’in “yeni bir optimizasyon algoritması” ve özel olarak hazırlanmış bir eğitim veri seti ile eğitildiğini açıklasa da, bu sürecin detayları henüz net olarak paylaşılmadı. Ancak, OpenAI’nin araştırma lideri Jerry Tworek, modelin “daha az hayali bilgi ürettiğini” ve doğruluk oranının arttığını belirtiyor. Yine de, modelin hala hatalı veya hayali bilgiler üretebildiği kabul ediliyor.
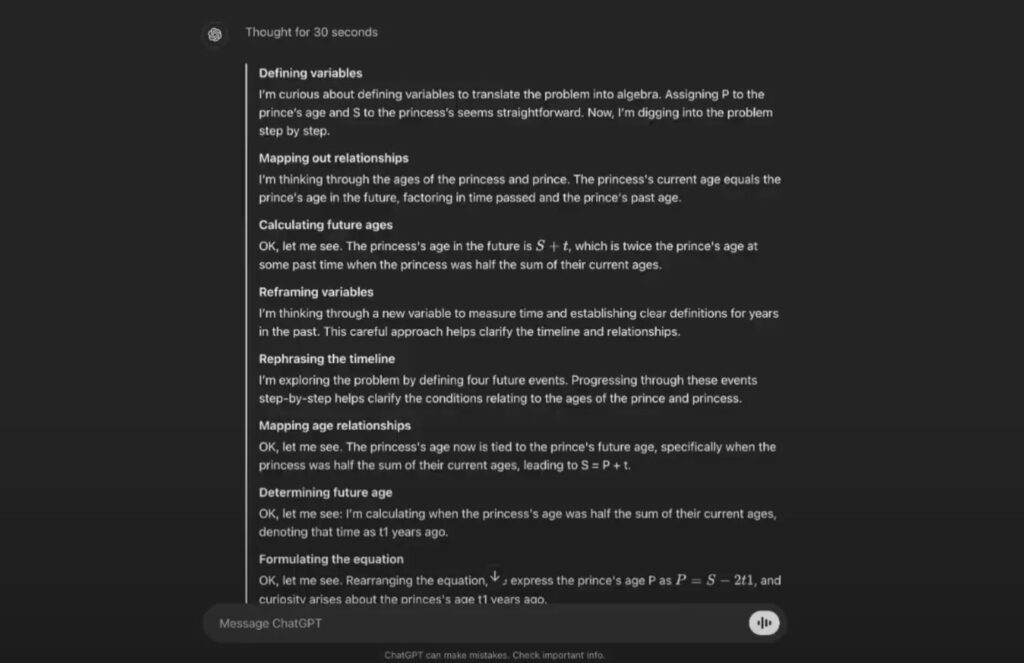
O1’in eğitim süreci, önceki GPT modellerinden önemli bir farklılık taşıyor. GPT modelleri, büyük veri setlerinden öğrendiği kalıpları taklit etmek üzere eğitilirken, o1 modeli, “pekiştirmeli öğrenme” (reinforcement learning) adlı bir teknikle eğitildi. Bu teknik, modele ödül ve ceza mekanizmaları aracılığıyla karar verme yeteneği kazandırıyor. Bunun yanı sıra, “zincirleme düşünme” (chain of thought) adı verilen bir yöntemle soruları adım adım çözme sürecine giriyor. Bu, insanların bir problemi parçalara ayırarak çözme yöntemine benzer şekilde çalışıyor.
Bu eğitim metodolojisi sayesinde modelin özellikle karmaşık matematiksel sorunlar ve kodlama işlemlerinde daha iyi performans gösterdiği belirtiliyor. Örneğin, Uluslararası Matematik Olimpiyatı’na hazırlık sınavında GPT-4o modeli yalnızca %13 doğru cevap verirken, o1 modeli bu soruların %83’ünü doğru çözmeyi başardı. Bu sonuç, modelin problem çözme yeteneklerinde önemli bir iyileşmeyi gösteriyor.
Daha fazla performans, daha yüksek maliyet
O1 modeli, birçok alanda GPT-4o’dan daha üstün performans sergilerken, bilgi doğruluğu konusunda aynı seviyede değil. Özellikle genel dünya bilgileri konusunda GPT-4o kadar başarılı olmadığı vurgulanıyor. Ayrıca, o1’in internet taraması yapma veya dosya ve görsel işleme yetenekleri bulunmuyor. Ancak, bu modelin daha geniş bir yetenek sınıfını temsil ettiğine inanılıyor. Modelin “o1” olarak adlandırılması, bu alanda bir tür “sıfırlama” ve yeni bir başlangıç olarak nitelendiriliyor.
OpenAI’nin yeni modeline yönelik yapılan gösterimlerde, modelin karmaşık soruları çözme sürecinde adeta insan benzeri düşünme tarzını taklit ettiği gözlemlendi. Örneğin, bir matematik sorusunu çözmeye çalışırken, modelin “Merak ediyorum”, “Düşünüyorum” ve “Tamam, bir bakalım” gibi ifadeler kullanarak adım adım düşündüğü izlenimi verdiği görüldü. Bu yaklaşım, modele insan benzeri bir çalışma tarzı kazandırsa da, yapay zekânın aslında insan gibi düşünmediği unutulmamalı.
OpenAI’nin o1 modeliyle başardığı en büyük yeniliklerden biri, yapay zekânın karar alma ve problem çözme yeteneklerini daha da geliştirme yolunda önemli bir adım atması. Bu gelişmeler, gelecekte otonom sistemler veya karar verme yetisine sahip “ajanlar” gibi ileri düzey yapay zekâ sistemlerinin yolunu açabilir. O1’in hâlâ yavaş ve maliyetli bir model olduğu kabul edilse de, bu modelin yapay zekânın insan benzeri zekâya ulaşma hedefinde kritik bir kilometre taşı olduğu düşünülüyor.










Bir yanıt yazın